
Part of the pleasure and challenge of case study research is establishing grounds for authorizing what we come to know about some phenomenon based on others’ words. In this section, we explain how we come to know what we know, addressing some of the most pressing methodological issues of collaborative, collective case study research.
[fruitful_tabs type=”accordion” width=”100%” fit=”false”]
[fruitful_tab title=”Collective Case Study Research”]We adopted a collective case study approach to this project, focusing on three students from our small random sample (52 students).
With collective (or “multiple” or “multi”) case study approach, researchers investigate a particular phenomenon highlighted by multiple cases, sometimes in an effort to inquire into different ways of understanding the issue (Cresswell 74). Because of the depth of analysis required in case study research, typically no more than a handful of cases are developed (76). A collective case studies approach allows for description-thick profiles to be drawn respecting individuals and their differences, all too easily collapsed in wider scale approaches.
At the core of each of the case studies are two interviews conducted with each student subject in the last semester or two of their senior year. One interview is a peer-to-peer interview conducted by a student-researcher associated with a campus Survey Research Center. The second interview is a semi-structured, document-based interview with the student conducted by two members of the research team.
Creswell, John W. Qualitative Inquiry & Research Design: Choosing Among Five Approaches. 2d Ed. Thousand Oaks, CA: Sage, 2007.
[/fruitful_tab]
[fruitful_tab title=”Collaborative Coding”]
In research that is qualitative, often researchers organize and begin to analyze their data by attaching “codes” (or labels) to select segments of text–an activity called “coding.” Those who pursue collaborative research frequently code collaboratively. Why?
Multiple minds bring multiple ways of analyzing and interpreting the data . . . Provocative questions are posed for consideration that could possibly generate new and richer codes. (Saldaña 27)
Yet one of the major challenges of coding collaboratively is coordinating the efforts of multiple researchers. In Phase 1 of our research project, we used spreadsheets in Google Drive as a simple yet effective means of collaborative coding. (At this point, we were coding brief written narratives at two levels of coding.)
Phase 2 of the project presented additional challenges for collaborative coding, namely coordinating coding across several different documents (e.g., transcribed interviews, student essays) at multiple levels. Computer assisted qualitative data analysis software (CAQDAS) has long offered researchers the option of using computers to code. (Well known CAQDAS include programs like NVivo and Atlas.ti.) Recently, CAQDAS has begun to facilitate researchers’ collaborative coding by allowing different users to code independently and then upload and combine their coding.
There are a number of CAQDAS with collaborative coding features. The CAQDAS Networking Project offers overviews of different CAQDAS, highlighting strengths and limitations. We opted to go with MAXQDA because of our project’s priorities: ease of use/intuitiveness and equivalent operation on both Mac and PC. (Project researchers would be using their individual laptops to code.) Our university did not have an institutional license, so we used grant funding (about $2,500 in 2016) to purchase six individual licenses.
Computer Assisted Qualitative Data Analysis Software CAQDAS Networking Project. University of Surrey, http://www.surrey.ac.uk/sociology/research/researchcentres/caqdas/resources/
Lewins, Ann and Christina Silver. Using Software for Qualitative Data Analysis: A Step-by-Step Guide. London, UK: Sage, 2007.
Saldaña, Johnny. The Coding Manual for Qualitative Researchers. London, UK: Sage, 2009.
[/fruitful_tab]
[fruitful_tab title=”Our Coding: Multi-Level, Multi-Cycle Coding and Collaborative Coding Protocol”]Using our chosen computer-assisted qualitative data analysis software (MAXQDA), we collaboratively coded each student interview transcript, working in pairs and pairing writing faculty and librarians to the extent possible.
Initially, we employed structural coding related to our research questions in order to provide a kind of index to relevant data in our transcripts (Saldaña 66-70, see table below).
Structural Codes Based on Research Questions
Structural Codes Based on Research Questions
| Research Questions | Structural Codes |
| How do students understand research and writing? As connected? | understand research
understand writing |
| How have their understandings changed? | change |
| To what do they attribute influence? | influence |
Each pair included a member who had trained with certain other team members on structural coding. This earlier working group had developed instructions and a code log for structural coding in order to enhance consistency and consensus. As a means of training, pairs structurally coded the first few pages of a student transcript independently and then met to discuss, focusing especially on any differences and working to achieve consensus. Each member of the pair then structurally coded the rest of the transcript independently and the pairs met once again to reconcile their coding. Persistent questions or differences were noted by pairs in memos and then brought to the team as a whole for discussion and resolution.
Next, to get at greater nuance with respect to transcripts, we conducted nested descriptive coding (70-73) at two additional levels. That is, each descriptive code included a more general “topic” code and a more specific “subcode,” sometimes drawing on the student’s own words (or “in vivo” coding). Each two-level descriptive code was further associated with a structural code, so that in this first cycle of coding, relevant interview text was coded at three levels (see screenshot below).
Example of Structural and Descriptive Coding in MAXQDA
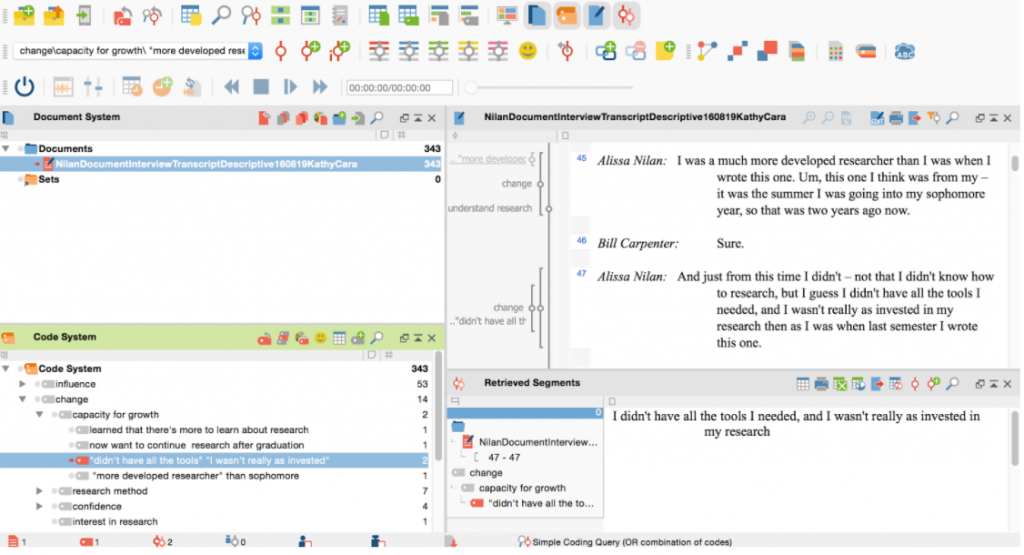
The protocol for descriptive coding was similar in many ways to the processes used for structural coding. Initial training on descriptive coding occurred on small sections of student interview transcripts at a meeting of the research team as a whole (rather than a smaller working group), in order to ensure a level of consistency and consensus. As with structural coding, pairs initially trained on descriptive coding by coding a section of their interview transcripts, writing up significant issues and resolutions in memos for discussion by the team as a whole. Structural coding had been more deductive, given that codes were derived from research questions, while descriptive coding was necessarily inductive, generated from student responses (even their very language). A coding log was compiled, this time in a collaborative electronic document by individual research team members as they worked to code. This code log included a brief description of and guidelines for descriptive coding as well as instructions on how to contribute to the code log. Specific descriptive codes were included along with examples associated with specific coders. Team members simultaneously contributed to this document and reviewed it for possible codes already created by others working with different student interview transcripts. This protocol allowed researchers to work independently while also achieving some consensus in descriptive codes applied. Unlike with structural coding, pairs eventually divided up the work of descriptive coding the interviews, individually labeling most of the transcripts at this level.
At this point, we began to analyze at a higher level in preparation for writing up individual case memos. In order to do so, we undertook a kind of second cycle coding known as pattern coding (Saldaña 152-55, Miles et al 86-91). Similarly coded passages within each case were collected and assigned pattern codes in order to identify themes, explanations, and possible theoretical constructs. Pattern coding was to serve as a relatively detailed outline for writing up individual case memos, connecting findings for an individual student regarding each of the research questions with specific, detailed evidence coded in the student’s interview transcripts. Within each pair, researchers divided the work of memo writing by each individual undertaking certain sections (with each section responding to a distinct research question). Inevitably, this writing process also influenced who primarily accomplished pattern coding for a section.
Miles, Matthew B., A. Michael Huberman, and Johnny Saldaña. Qualitative Data Analysis: A Methods Sourcebook. Ed. 3. Thousand Oaks, CA: Sage, 2014.
Saldaña, Johnny. The Coding Manual for Qualitative Researchers. London, UK: Sage, 2009.
[/fruitful_tab]
[fruitful_tab title=”Triangulation”]Case study researchers in our discipline (among others) will find very few protocols with respect to triangulation. This may in part be due to the variety of ways in which researchers understand triangulation, both philosophically and as far as approach. In our current work, we adopt a constructivist orientation to triangulation that values more interpretive approaches (Stake, The Art, 115)–e.g., appreciating the richness and complexity of understanding enabled by multiple perspectives. Here, we discuss the ways that data triangulation and investigator triangulation has informed our research.
Data Triangulation
When a researcher uses data triangulation, she “look[s] to see if the phenomenon or case remains the same at other times, in other places or as persons interact differently” (Stake, The Art, 112). The many data sources of our project offer numerous possibilities for this kind of triangulation. At this point, we are most interested in data triangulation with respect to the theme of “influence”–to what students attribute their shaping influences as researchers and as writers. Specifically, students identified faculty as influential, in ways both positive and negative. What might we learn about faculty’s influence by triangulating one data source with another–i.e., triangulating student interview data with faculty interview data?
With this question in mind, we designed and employed the following protocol for data triangulation: Three individual researchers were each assigned to read a student case memo for mentions of “professor,” especially in the sections of the memos on the theme of influence. The researcher also reviewed related the interview transcripts for faculty who had worked with the student, focusing especially on moments in which faculty spoke to issues raised by a student (e.g., the interpersonal relationship between a student and faculty member, taking your research as far as you want, strictness in researching, etc.) The faculty interviews were used to make a more complete, richer sense of what the student spoke of (e.g., how the faculty member perceived the relationship, accreditation guidelines as motivation for teaching research in a certain way, etc.). Faculty interviews were also used to fill out factual details about courses, assignments, etc.)
By employing the protocol, we were able to secure and enrich those findings related to student’s sense of faculty’s influence on them as researchers and writers. Most significantly, we found that meaningful research and writing experiences can happen for undergraduates when faculty provide guidance and feedback on research and writing that is taken up by students, and they more often remember students and their projects.
Stake, Robert E. The Art of Case Study Research. Thousand Oaks, CA: Sage, 1995.
Investigator Triangulation
Investigator triangulation (IT) involves multiple researchers with “some diversity of skills, training, or disciplinary backgrounds” (Archibald 232) who together examine a “scene” or phenomenon (Stake 113). IT has several purposes, including generating multiple perspectives and diverse ways of interpreting data, reducing researcher bias, and checking consistency or coming to consensus (especially with respect to coding) (Archibald 240-43). Research projects like ours–collaborations among colleagues–provides rich opportunities for IT.
One aspect of IT is the diversity of perspectives that researchers bring to a project by virtue of their differing backgrounds, training, disciplinary orientation, and professional responsibilities. Our own research team of writing faculty and librarians [link to bios] bring to bear differences (especially disciplinary) that ideally reduce bias and generate multiple ways of understanding.
IT also was pursued as a means for somewhat contradictory goals held generatively in tension with one another: interpreting data diversely as well as coming to consensus. These aims were accomplished via IT in research protocols, including those protocols employed for data coding (see Our Coding above). As just one example, we incorporated IT at the level of structural coding by assigning cases to researcher pairs that leveraged the diversity of our team members’ respective background and training, fostering role independence and multiple perspectives. The protocol itself allowed each pair member independence in reaching his or her own conclusions before collaborating as a pair and then as a team toward consensus.
Well designed collaborative research can be more than collegial and practice-oriented. Collaboration ideally contributes to the quality of what we come to know by relying on researchers themselves–their variety of backgrounds and perspectives–to triangulate analysis.
Archibald, Mandy M. “Investigator Triangulation: A Collaborative Strategy With Potential for Mixed Methods Research.” Journal of Mixed Methods Research 10.3 (2016) 228-50.
Stake, Robert E. The Art of Case Study Research. Thousand Oaks, CA: Sage, 1995.
[/fruitful_tab]
[fruitful_tab title=”Cross-Case Analysis”]One challenge of collective case study research involves how a researcher makes sense of a phenomenon across multiple cases, known as “cross-case analysis” (or “multiple case analysis”). As is noted by a recent article on the topic:
With notable exceptions (Stake, 2006; Yin, 2012), there are few exemplars of applied cross-case analysis in the literature. The unique circumstances of a multicase study project raise different methodological questions than single-case analysis . . . (Fletcher et al. 2)
In developing a protocol for cross-case analysis, we addressed several conceptual questions (drawn from Fletcher et al):
- What is the unit of cross-case analysis? For our purposes, we designated as our unit the student (as a case and as a participant).
- What material should be subjected to cross-case analysis? Aggregated raw data from all case studies (see, e.g., Purcell-Gates et al 454)? Individual case memos (or “case study reports”) (see e.g., Fletcher et al 6)? We already had accomplished a good deal of analysis in our individual case memos. Additionally, by returning to raw data, researchers can risk losing the context developed via the case (see Stake). It made sense to use these memos as the primary material for our cross-case analysis, turning to interview transcripts and soundfiles only as needed.
- How should this material be analyzed across cases (i.e., cross-case analysis protocol)?
We opted to use a modified version of Robert E. Stake’s protocol as described in Multiple Case Study Analysis. (For another approach in a participatory research context, see Fletcher et al.) We regrouped in working groups of three (each with two writing faculty and a librarian). Cross-case analysis involved individually reading the sections of each of the case memos having to do with a particular research question or structural code in order to determine the significant findings from each memo with respect to this question. We trained as a full team by working together on the research question regarding change, and then met as working groups to come to consensus on what the significant findings were for other research questions. Findings were organized from most to least useful for understanding the research question, allowing for individual differences and possible contradictions. As Stake notes, one of the risks of cross-case analysis is that researchers can rush too quickly to similarities shared by cases without sufficiently acknowledging outlying aspects, a challenge he attempts to address in his protocol (54-55).
Fletcher, Amber J., Maura MacPhee, and Graham Dickson. “Doing Participatory Action Research in a Multicase Study: A Methodological Example.” International Journal of Qualitative Methods (2015): 1–9
Purcell-Gates, Victoria and Kristin Perry. “Analyzing Literacy Practice: Grounded Theory to Model”, RTE 45 (May 2011). 439-58.
Stake, Robert E. Multiple Case Study Analysis. New York: The Guilford Press, 2006.
[/fruitful_tab]
[/fruitful_tabs]
[fruitful_ibox_row]
[fruitful_ibox column=”ffs-two-one” title=”Previous Section”]Data Collection Tools[/fruitful_ibox]
[fruitful_ibox column=”ffs-two-one” title=”Next Section” last=”true”]Findings[/fruitful_ibox][/fruitful_ibox_row]